Trong bài viết này, tôi sẽ hướng dẫn bạn những điều mà tôi nghĩ cần có để trở thành 1 iOS Developer. Tôi muốn nhắm vào 2 nhóm người:
- Những người mới bắt đầu làm quen với Swift – những người chưa từng xây dựng bất kỳ thứ gì cho iOS trước giờ – và
- Những người được gọi là false beginner, bạn đã cố gắng học Swift trước đây nhưng chưa bao giờ thực sự đạt được mục tiêu kiếm việc làm toàn thời gian.
Bất kể bạn hiện đang ở cấp độ nào, mục tiêu ở đây đều giống nhau: Đưa bạn vào đúng nợi để ứng tuyển vào vị trí Junior iOS Developer tại một công ty.
Dừng lại chút nào, nếu bạn đang #open_to_work, thử nghía qua các công việc đang tuyển trên Gamba nhé. Vào LINK NÀY để xem các job cần đến kỹ năng iOS hoặc scan QR Code ở bên dưới nhé.


Chúng ta sẽ xem xét các kỹ năng bạn nên học, các khóa học bạn có thể tham gia, cách kết nối với cộng đồng, những lỗi thường gặp của mọi người,… mà không phải bỏ ra xu nào để học.
Nghiêm túc mà nói, có quá nhiều người nghĩ rằng tiêu tiền là con đường nhanh nhất để đạt được công việc mơ ước của họ, trong khi điều thực sự quan trọng nhất là sự quyết tâm và ý chí.
Có 7 phần trong bài viết này:
- Những kỹ năng cốt lõi bạn nhất thiết phải biết để có 1 công việc.
- Các kỹ năng mở rộng – những kỹ năng sẽ khiến bạn trở nên khác biệt, nếu bạn có thời gian để học chúng
- Những sai lầm phổ biến mọi người mắc phải khi họ cố gắng học hỏi.
- Các tài nguyên (miễn phí) để học Swift.
- Cách kết nối với cộng đồng phát triển iOS.
- Ý tưởng về việc mất bao lâu để đạt được mục tiêu.
- Chuẩn bị nộp đơn cho công việc đầu tiên
Những kỹ năng cốt lõi để trở thành iOS Developer
Bộ kỹ năng tối thiểu bạn cần để có được công việc trong lĩnh vực phát triển iOS là gì? Tôi nghĩ tổng cộng có 5 món:
- Swift
- SwiftUI
- Làm việc với dữ liệu
- Kết nối mạng
- Kiểm soát phiên bản
Hết rồi. Và danh sách đó là siêu ngắn có chủ đích, vì một số lý do:
Bạn càng học nhiều, bạn càng nhận ra rằng còn nhiều thứ phải học, vì vậy bạn rất dễ dành nhiều thời gian cho việc học và thực hành đến mức đánh mất mục tiêu thực tế – đó là kiếm một công việc với tư cách là iOS developer chứ không phải chỉ ngồi học tùm lum thứ.
Gần như chắc chắn bạn sẽ tham gia một nhóm đã có sẵn ứng dụng mà họ muốn bạn giúp phát triển, vì vậy trừ khi bạn cực kỳ may mắn, họ sẽ cần dạy bạn rất nhiều thứ bất kể – nếu bạn cố gắng và nhồi nhét về các chủ đề bổ sung trước đó, rất có thể bạn đang lãng phí thời gian của mình.
2 trong số 5 thứ đó thực sự lớn và thực sự phức tạp, và bạn có thể mất hàng tháng trời chỉ để cố gắng quấn lấy chúng mà không muốn mạo hiểm ở bất kỳ nơi nào khác.
Nhưng quan trọng nhất, nếu bạn làm đúng năm điều đó, bạn có thể xây dựng một loạt các ứng dụng.
Chắc chắn, code của bạn sẽ không hoàn hảo nhưng điều đó không sao – cách duy nhất để viết code xuất sắc là viết một loạt mã tệ trước đó.
Để nói chi tiết 5 cái này hơn nhé.
Học Swift
Đầu tiên trong danh sách là Swift.
Đây là ngôn ngữ lập trình cốt lõi của Apple – nó không có khái niệm hiển thị thông tin trên màn hình iPhone hoặc tải xuống dữ liệu từ internet, nó chỉ là một ngôn ngữ như JavaScript hoặc Python.
Bạn sử dụng nó để tạo biến, viết hàm,… nó chỉ là mã thuần túy.
Swift chỉ mới được vài năm tuổi, có nghĩa là nó sử dụng hầu hết mọi tính năng ngôn ngữ tiên tiến hiện có.
Một mặt, điều này nghĩa là bạn có thể tránh tất cả các hành vi cũ kỹ thường gặp trong các ngôn ngữ cũ hơn như C ++ và Java, nhưng nó cũng có nghĩa là nó có một số tính năng nâng cao hơn có thể khiến bạn hơi choáng lúc đầu.
Và điều đó không sao cả: nhiều phần của Swift tương đối đơn giản và một số phần sẽ khiến bạn mất nhiều thời gian hơn để thực sự hiểu ra, vì vậy chỉ cần dành thời gian và tiếp tục – bạn sẽ đạt được điều đó!
Học SwiftUI
Kỹ năng cốt lõi thứ hai mà tôi liệt kê là SwiftUI, đây là một framework của Apple cho phép chúng ta viết ứng dụng cho iOS, macOS, tvOS và thậm chí watchOS bằng Swift.

Vì vậy, trong khi Swift là ngôn ngữ lập trình, SwiftUI cung cấp các công cụ tạo ứng dụng – cách hiển thị ảnh, văn bản, nút, hộp văn bản, bảng dữ liệu,…
Cần nói rõ là, SwiftUI không phải để thay thế Swift – nó là một khung được xây dựng dựa trên Swift cho phép chúng ta tạo ứng dụng, vì vậy bạn cần cả Swift và SwiftUI để thành công.
Nếu bạn nghĩ Swift là mới, thì bạn vẫn chưa thấy gì – vì SwiftUI này chưa được hai năm tuổi! Nhưng mặc dù mới, nhưng cộng đồng iOS đã hết lòng đón nhận nó vì làm việc trên đó rất tuyệt.
Apple có một framework cũ hơn cho việc xây dựng ứng dụng iOS được gọi là UIKit và nếu bạn hỏi rằng bạn nên học SwiftUI trước hay UIKit trước, bạn sẽ nhận được nhiều câu trả lời.
Trên thực tế, bạn sẽ thấy nhiều người nói rằng họ không biết tôi đang nói về điều gì và UIKit nên được ưu tiên.
Trong trường hợp bạn thắc mắc, đây là lý do tại sao tôi nghĩ bạn nên tập trung vào SwiftUI như một kỹ năng cốt lõi:
- Nó dễ dàng so với UIKit, và ý tôi là dễ hơn đáng kể – có thể chỉ mất 1/4 code trên SwiftUI để nhận được kết quả tương tự như trên UIKit, ngoài ra bạn có ít thứ phải học hơn. Điều này nghĩa là bạn sẽ có rất nhiều động lực vì xây dựng mọi thứ nhanh hơn, xem kết quả của mình nhanh hơn và lặp lại các kết quả đó nhanh hơn.
- SwiftUI được xây dựng cho Swift, sử dụng các tính năng ngôn ngữ để giúp bạn tránh các vấn đề và đạt được hiệu suất tối đa. Ví dụ: nếu bạn thay đổi một số dữ liệu trên một màn hình của ứng dụng, SwiftUI sẽ tự động đảm bảo dữ liệu mới được cập nhật ở bất kỳ nơi nào khác trong ứng dụng của bạn sử dụng dữ liệu đó – bạn không cần phải viết mã đồng bộ hóa, chỉ làm mọi thứ thêm phức tạp. Trong khi đó, UIKit được viết cho ngôn ngữ cũ hơn của Apple, Objective-C, và kết quả là có đủ thứ kỳ quặc và rắc rối xuất hiện do tuổi tác của nó.
- SwiftUI hoạt động trên tất cả các nền tảng của Apple, vì vậy bạn có thể tận dụng những gì đã học trên iOS và sử dụng nó để tạo ứng dụng macOS hoặc watchOS với code gần như giống hệt nhau. Một số thứ như Digital Crown chỉ tồn tại trên một thiết bị, nhưng phần lớn những gì bạn học được sẽ chạy được ở mọi nơi.
- Nhưng quan trọng nhất, SwiftUI là nơi mọi thứ diễn ra. Nếu lúc này bạn đang nộp đơn ứng tuyển thì vẫn sẽ ổn nếu bạn cần biết UIKit. Đúng là UIKit hiện đã phổ biến hơn, nhưng vào thời điểm bạn học xong 6, 9 hoặc thậm chí 12 tháng kể từ bây giờ, SwiftUI sẽ là UI framework thống trị.
Nghiêm túc mà nói, các công ty lớn nhất thế giới đang chọn SwiftUI, bao gồm cả chính Apple, và khi Apple mới ra mắt các widget trong iOS 14, họ đã đưa ra yêu cầu rằng bạn phải sử dụng SwiftUI – UIKit không thể thực hiện được ở đó.
Mạng và dữ liệu
Kỹ năng thứ ba và thứ tư mà tôi đã đề cập là kết nối mạng và làm việc với dữ liệu. So với Swift và SwiftUI, thì nó khá dễ, hoặc ít nhất chúng ở cấp độ bạn cần để có được vị trí Junior iOS developer.

Kết nối mạng (networking) là hoạt động tìm nạp dữ liệu từ internet hoặc gửi dữ liệu từ thiết bị cục bộ đến máy chủ ở đâu đó.
Có nhiều cách để thực hiện việc này, nhưng thành thật mà nói thì điều tối thiểu bạn cần biết là cách tìm nạp một số JSON từ máy chủ.
Và đó là lúc một kỹ năng cốt lõi khác xuất hiện: làm việc với dữ liệu.
Có rất nhiều cách để bạn có thể tải và lưu dữ liệu, nhưng điều tối thiểu nhất bạn cần làm là chuyển đổi dữ liệu bạn nhận được từ máy chủ sử dụng mã mạng (network code) của bạn thành một số thông tin mà ứng dụng của bạn có thể hiển thị.
Vì vậy, thực sự kỹ năng cốt lõi thứ ba và thứ tư đi đôi với nhau: tìm nạp dữ liệu từ máy chủ, sau đó chuyển đổi nó thành thông tin mà bạn có thể hiển thị trong ứng dụng của mình.
Một số developer nói đùa rằng loại mã này là một nửa công việc của các iOS Developer và chắc chắn là chúng ta sử dụng những kỹ năng này rất nhiều.
Và cuối cùng: kiểm soát phiên bản
Kỹ năng cuối cùng hoàn toàn không phải là mã hóa: đó là kiểm soát phiên bản, sử dụng một cái gì đó như Git.
Bạn thực sự không cần nhiều ở đây, nhưng điều quan trọng là bạn có thể xuất bản code của mình ở một nơi nào đó như GitHub để các nhà tuyển dụng có thể xem công việc của bạn một cách công khai.
Tôi không nghĩ rằng bất kỳ ai trên đời này thực sự hiểu mọi thứ về cách hoạt động của Git, nhưng không sao – bạn chỉ cần biết đủ kiến thức cơ bản để lưu trữ dữ liệu của mình một cách an toàn và có thể làm việc với những người khác.
Vì vậy, gộp 5 cái đó lại với nhau thì có 2 cái lớn – Swift và SwiftUI – cộng với 3 cái nhỏ nhưng quan trọng.
Thành thật mà nói, nếu bạn có thể chỉ tập trung vào 5 cái đó mà không bị phân tâm, bạn sẽ có những bước tiến lớn đối với công việc iOS Developer đầu tiên của mình.
Đó là 5 kỹ năng cốt lõi mà tôi nghĩ bạn cần để trở thành một nhà phát triển iOS.
Có hàng nghìn người ngoài kia chỉ có những kỹ năng đó và có thể xây dựng và đưa ra các ứng dụng tuyệt vời trên App Store.
Còn gì sau các kỹ năng cốt lõi của iOS Developer?
Khi bạn đã thực sự nắm chắc 5 kỹ năng cốt lõi, bạn hoàn toàn có thể tự vận hành các ứng dụng của riêng mình và làm việc với tư cách là một nhà phát triển độc lập, đồng thời cũng có thể ứng tuyển vào các vị trí Junior iOS developer và làm việc cho công ty bạn muốn.
Không có bằng cấp đặc biệt nào khác mà bạn cần – hãy học những kỹ năng cốt lõi đó.
Nhưng nếu bạn đã làm việc theo cách của mình thông qua các kỹ năng đó và muốn tiến xa hơn, thì có năm kỹ năng mở rộng mà tôi khuyến khích bạn học.
Đây là những kỹ năng sẽ đưa bạn từ nơi tốt sang nơi tuyệt vời – bạn thậm chí còn trở nên dễ được tuyển hơn và phạm vi ứng dụng bạn có thể xây dựng sẽ còn phát triển hơn nữa.
Các kỹ năng là:
- UIKit
- Dữ liệu lõi (Core Data)
- Kiểm thử
- Kiến trúc phần mềm
- Đa luồng
Tôi muốn giải thích chi tiết hơn từng cái để bạn có thể hiểu tại sao chúng quan trọng – và tại sao tôi coi chúng là kỹ năng mở rộng hơn là kỹ năng cốt lõi.
Chuyển sang UIKit
Đây là khung giao diện người dùng cũ hơn của Apple và đã được sử dụng để xây dựng ứng dụng từ năm 2008 – nó đã 13 năm tuổi khi tôi viết bài này, theo thuật ngữ phần mềm thì đã cũ.
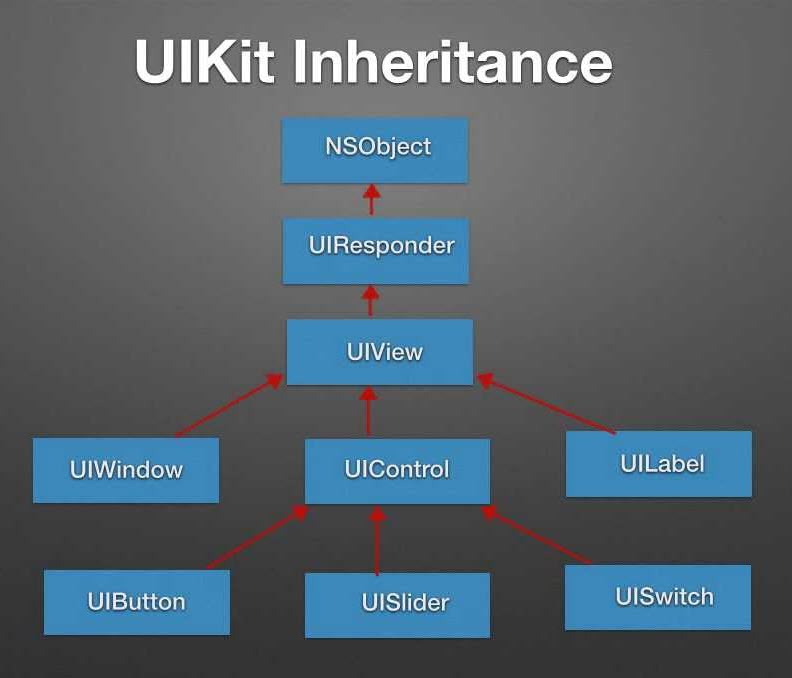
Nhưng độ tuổi đó không có nghĩa là UIKit tệ, và thực tế là khi bạn cảm thấy thoải mái với cách thức hoạt động của nó, bạn sẽ ngạc nhiên bởi vẻ đẹp của nó.
Có rất nhiều điều khiến UIKit đáng học hỏi, bao gồm:
- Hàng trăm nghìn ứng dụng đã được viết trong UIKit, vì vậy nếu bạn đang gia nhập một công ty có ứng dụng lớn, được thiết lập tốt, bạn gần như chắc chắn sẽ cần viết mã UIKit để duy trì ứng dụng đó.
- UIKit mạnh hơn đáng kể so với SwiftUI – có nhiều điều bạn có thể làm trong UIKit mà SwiftUI không thể thực hiện được tại thời điểm này.
- Bạn có thể tạo các bố cục cực kỳ chính xác bằng cách sử dụng công nghệ có tên là Bố cục Tự động (Auto Layout).
- Nếu bạn gặp sự cố với mã của mình, có nhiều giải pháp có sẵn trong UIKit hơn SwiftUI, đơn giản vì nó đã tồn tại lâu hơn nhiều.
Bạn có thể nghĩ rằng tất cả những điều đó làm cho UIKit trở nên tuyệt vời, vậy tại sao tôi lại biến nó thành một kỹ năng mở rộng thay vì một kỹ năng cốt lõi?
Chà, vì UIKit cũng có vấn đề:
- Hầu hết mọi thứ trong UIKit đều khó thực hiện hơn SwiftUI, với một số thứ tốn nhiều mã gấp hàng trăm lần nếu không muốn nói là nhiều hơn. SwiftUI được tạo ra đặc biệt cho phát triển iOS hiện đại, vì vậy nó thực hiện rất nhiều công việc cho bạn.
- Vì UIKit không được viết cho Swift, bạn sẽ thấy nó có nhiều tính năng mà bạn có thể quên với SwiftUI – rất nhiều tùy chọn không được bao bọc ngầm, đánh dấu mã bằng thuộc tính @objc đặc biệt để làm cho nó có sẵn cho Objective-C của UIKit, cần sử dụng giao thức và đại biểu để hiển thị dữ liệu đơn giản.
- Không có gì về Bố cục Tự động là “tự động” – trên thực tế, nếu bạn cố gắng tạo một bố cục phức tạp, rất có thể bạn sẽ gặp ác mộng về Bố cục Tự động. Nó cực kỳ thông minh, nhưng nó cũng cực kỳ khó khăn.
Và đó là lý do tại sao tôi coi UIKit là một kỹ năng mở rộng: cần nhiều thời gian và nỗ lực để học so với SwiftUI, điều này có nghĩa là cần phải quyết tâm hơn rất nhiều – bạn phải thực sự muốn học nó, nếu không thì bạn sẽ bối rối, buồn chán, tức giận, hoặc có thể là cả ba.
Chắc chắn, SwiftUI không có tất cả các tính năng của UIKit, nhưng ít nhất bạn có thể đạt được tiến bộ nhanh chóng và cảm thấy có động lực cũng như thành công trước khi chuyển sang UIKit.
Xử lý dữ liệu lõi
Kỹ năng mở rộng thứ hai mà tôi đã đề cập là Dữ liệu lõi, là framework của Apple để làm việc với dữ liệu ứng dụng.

Trong phần kỹ năng lõi, tôi đã liệt kê cả kết nối mạng và làm việc với dữ liệu và đúng là như vậy: với những kỹ năng đó, bạn có thể tìm nạp bất cứ thứ gì bạn muốn từ máy chủ và hiển thị nó trong ứng dụng của mình.
Những gì Core Data thực hiện còn tiến xa hơn một bước: nó cho phép bạn thao tác dữ liệu đó khi bạn có nó, chẳng hạn như tìm kiếm các giá trị cụ thể, sắp xếp kết quả, v.v., tất cả đều rất hiệu quả.
Nó cũng có thể liên kết rất dễ dàng với iCloud, có nghĩa là dữ liệu của người dùng của bạn được đồng bộ hóa trên tất cả các thiết bị của họ.
Dữ liệu lõi có rất nhiều nhược điểm, trong đó nhược điểm lớn nhất thường không được thoải mái cho lắm khi làm việc.
Core Data có tuổi đời tương đương với UIKit, và mặc dù nó hoạt động tốt với Objective-C nhưng nó không thoải mái bằng Swift.
Nó có tích hợp tốt với SwiftUI, điều này làm cho nó đỡ lạ hơn một chút, nhưng nó vẫn là một chủ đề phức tạp tới mức kinh ngạc.
Vì vậy, tại sao tôi lại liệt kê nó như một kỹ năng mở rộng? Bởi vì giống như UIKit, Dữ liệu lõi cũng cực kỳ phổ biến – hàng trăm nghìn ứng dụng đã được xây dựng bằng cách sử dụng nó và nó được sử dụng ở nhiều công ty lớn và nhỏ.
Cũng giống như UIKit, Core Data thực sự mạnh mẽ và mặc dù bạn có thể tạo lại những phần quan trọng nhất của nó trong mã của riêng mình, nhưng tại sao bạn lại muốn như thế chứ?
Chứng minh mã của bạn hoạt động
Kỹ năng thứ ba trong danh sách mở rộng của tôi là kiểm thử: viết mã đặc biệt để kiểm tra mã ứng dụng chính của bạn có hoạt động theo cách bạn mong đợi hay không.

Các kiểm thử cho phép chúng ta đảm bảo mã của mình hoạt động chính xác và quan trọng hơn cho phép chúng ta tiếp tục đảm bảo mã hoạt động chính xác ngay cả sau khi chúng ta đã thực hiện các thay đổi quan trọng đối với nó – nếu bạn thay đổi 500 dòng mã để triển khai một tính năng mới và tất cả bài kiểm thử đều qua, thì cứ thế mà đi.
Vì vậy, kiểm thử rất quan trọng, và sẽ giúp bạn viết phần mềm có chất lượng tốt hơn. Vậy tại sao nó là một kỹ năng mở rộng thay vì một kỹ năng cốt lõi? Có ba lý do:
- Vì bất kỳ lý do lịch sử nào, cộng đồng iOS nói chung rất tệ khi nói đến kiểm thử. Ý tôi là thực sự rất tệ – nhiều ứng dụng khổng lồ hầu như không có bất kỳ bài kiểm thử nào và tôi đã không đếm được bao nhiêu senior iOS developer mà mình từng gặp, những người gần như tự hào rằng họ không bao giờ viết kiểm thử.
- Khi bạn nghĩ về tất cả những thứ đáng chú ý mà bạn có thể xây dựng bằng các công cụ và framework của Apple, thành thật mà nói, viết kiểm thử có vẻ không thú vị lắm. Cá nhân tôi thích viết các bài kiểm thử giống như cách tôi thích xỉa răng, nhưng tôi biết nhiều người không cảm thấy hứng thú với chúng, đặc biệt là đối với các dự án cá nhân.
- Khi bạn đang ứng tuyển, việc có kiến thức về Swift và các framework chính của Apple sẽ luôn có lợi hơn kiến thức về các bài kiểm thử. Các công ty thà rằng bạn biết cách sử dụng SwiftUI, UIKit hoặc một trong những cái tên nổi tiếng khác, bởi vì kiểm thử là một chủ đề nhỏ hơn đáng kể – gần như không có nhiều thứ để tìm hiểu.
Vì vậy, kiểm thử là quan trọng, và tôi rất muốn bạn học cách viết các bài kiểm thử tuyệt vời.
Nhưng hãy làm điều đó sau khi bạn đã nắm được những kiến thức cơ bản về xây dựng ứng dụng – hãy đạt được một số thành công nhất định, cảm nhận sự phấn khích tuyệt đối khi ứng dụng của bạn xuất hiện trên App Store, sau đó bắt đầu kiểm thử.
Xây dựng thông minh hơn
Kỹ năng mở rộng thứ tư mà tôi muốn nói đến là kiến trúc phần mềm (software infrastructure), nó là về cách chúng ta tạo code của mình.

Khi bạn chỉ mới học, bạn sẽ viết mã tệ tới nỗi nó có thể phá vỡ hiệp định Geneva.
Và điều đó không sao cả, bởi vì đó là cách bạn học: bạn khởi đầu không tốt – bạn trở nên giỏi khi đã dở trong một thời gian dài, giống như LeBron James sinh ra không phải là một nhà vô địch bóng rổ.
Vấn đề là bạn phải kiên trì với đoạn mã kém của mình, cho đến khi bạn học cách làm nó tốt hơn.
Và đó là lúc kiến trúc phần mềm xuất hiện: áp dụng các kỹ thuật đã được chứng minh để cấu trúc mã của bạn để giúp dễ đọc hơn, dễ sử dụng hơn, dễ sửa đổi hơn và dễ chăm sóc về lâu dài hơn.
Đôi khi những kỹ thuật này dựa trên cách Swift hoạt động – các tính năng ngôn ngữ mà bạn có thể sử dụng để viết mã tốt hơn.
Nhưng có nhiều kỹ thuật khác hoạt động với bất kỳ ngôn ngữ lập trình nào, và chúng ta thường gọi là các mẫu thiết kế (design patterns).
Một điểm chính mà bạn nên bắt đầu tìm hiểu như một phần của kỹ năng này là cách chia nhỏ mã.
Ví dụ:
Nếu bạn đang tạo một màn hình trong ứng dụng của mình, bạn có thể có nút đăng nhập, thư viện hình ảnh và danh sách bạn bè trên màn hình đó.
Nhưng lý tưởng nhất là bạn nên tạo từng thành phần riêng biệt – thành phần nút đăng nhập, thành phần thư viện hình ảnh và thành phần danh sách bạn bè – để bạn có thể sử dụng lại bất kỳ thành phần nào trong số các thành phần đó trong các phần khác của ứng dụng.
Kiến trúc phần mềm mang tính chủ quan hơn nhiều so với các kỹ năng khác mà tôi đã đề cập cho đến nay.
Đối với những thứ khác – ví dụ như SwiftUI – bạn có thể tự nghĩ: “Chà, tôi biết cách thực hiện X, Y và Z, vì vậy tôi cảm thấy tự tin rằng mình là một nhà phát triển SwiftUI giỏi.”
Kiến trúc phần mềm là một chủ đề rất rộng và thành thật mà nói, không có cách nào rõ ràng là “đúng” để giải quyết vấn đề, vì vậy tôi nghĩ điểm chuẩn tốt nhất cho nó là: nếu bạn nhìn lại mã của mình từ sáu tháng trước, hoặc một năm trước, hoặc ba năm trước,… bạn có nghĩ “wow, mã đó tệ quá!”
Một lần nữa, code xấu cũng không sao miễn là nó đưa bạn đến con đường trở nên tốt hơn.
Tôi chắc chắn nhìn lại đoạn mã mà tôi đã viết cách đây 5 năm và nhăn mặt ở nhiều chỗ, bởi vì bây giờ tôi biết nhiều hơn những gì tôi đã làm hồi đó – và đó là một điều tốt.
Đa luồng (multithreading)
Kỹ năng mở rộng cuối cùng mà tôi muốn nói đến là đa luồng, nói một cách đơn giản là kỹ thuật làm cho mã của bạn làm nhiều việc cùng một lúc.
Đa luồng có thể là một vấn đề thực sự đau đầu, vì bộ não của chúng ta khó hiểu – khi code của bạn thực hiện một việc tại một thời điểm, chúng ta có thể suy nghĩ một cách tuyến tính, nhưng khi hai hoặc ba điều xảy ra cùng một lúc, có khả năng chồng chéo lên nhau, nó thực sự có thể uốn cong bộ não của bạn.
Vì vậy, mặc dù đa luồng là một điều tuyệt vời để có như một kỹ năng mở rộng, bạn cần phải cẩn thận – mục tiêu của bạn phải là hiểu vừa đủ các khái niệm và mã để làm cho nó hoạt động tốt mà không cần phải đi xa hơn.
Thành thật mà nói, nhiều nhà phát triển nghĩ rằng đa luồng sẽ làm cho mã của họ chạy nhanh hơn ba hoặc bốn lần ngay lập tức, và trong một số trường hợp thì sẽ như vậy, nhưng trong nhiều trường hợp khác, mã của bạn sẽ chạy chậm hơn và rồi bạn có một mớ phức tạp cần giải quyết.
Vì vậy: hãy tìm hiểu một chút về cách hoạt động của đa luồng trong Swift để bạn có thể hiểu được các khái niệm và cách triển khai, nhưng hãy cố gắng đừng đi quá đà!
Những sai lầm thường gặp của iOS Developer
Tại thời điểm này, tôi đã phác thảo tất cả các kỹ năng cốt lõi và mở rộng mà tôi nghĩ bạn cần để làm việc với tư cách là iOS Developer fulltime.
Nhưng tôi cũng muốn nói về một số sai lầm phổ biến nhất mà mọi người mắc phải khi học, bởi vì tôi thấy những lỗi này rất nhiều và tôi biết nó khiến mọi người phải lùi bước.
Có 7 vấn đề chính mà mọi người gặp phải, và tôi muốn trình bày chúng theo thứ tự. Chúng là:
- Ghi nhớ mọi thứ
- Hội chứng đồ vật sáng bóng (shiny object syndrome)
- Sói cô đơn
- Sử dụng phần mềm beta
- Dựa vào tài liệu của Apple
- Bị lạc trong Objective-C
- Thèm thuồng ngôn ngữ khác
Hãy cùng tìm hiểu từng cái.
Cố gắng ghi nhớ mọi thứ
Vấn đề đầu tiên và cho đến nay là vấn đề phổ biến nhất mà mọi người gặp phải là cố gắng ghi nhớ mọi thứ – đọc qua một hướng dẫn và nghĩ rằng họ phải ghi nhớ mọi thứ trong đó.
Xin đừng làm vậy: đó là công thức của thảm họa và sẽ hút hết ý chí ra khỏi bạn cho đến khi bạn không bao giờ muốn lập trình nữa.
Không ai ghi nhớ tất cả mọi thứ.
Không ai thậm chí đến gần việc ghi nhớ tất cả mọi thứ.
Ngay cả khi bạn chỉ nghĩ về các API mà Apple xuất bản, đó là những đoạn mã mà chúng ta có thể sử dụng để xây dựng ứng dụng của mình, thì cũng phải có hơn một trăm nghìn người ở đó.
Nếu bạn chỉ giới hạn điều đó ở các thành phần cốt lõi của xây dựng ứng dụng, thì có thể bạn vẫn đang xem xét hàng trăm – tất cả đều hoạt động theo một cách rất chính xác đòi hỏi nhiều học hỏi để sử dụng.
Thay vào đó, điều xảy ra là bạn học cách làm điều gì đó mới, sau đó nhanh chóng quên nó đi.
Vì vậy, bạn tra cứu nó và sử dụng nó một lần nữa, sau đó kịp thời quên nó đi. Vì vậy, bạn tra cứu nó lần thứ ba và sử dụng nó, và lần này bạn hầu như chỉ quên nó – một số bộ phận vẫn còn trong não của bạn.
Điều này lặp đi lặp lại, mỗi lần bạn phải tham khảo một hướng dẫn hoặc một số hướng dẫn tham khảo khác, cho đến khi cuối cùng những điều thực sự cốt lõi đã bám vào đầu bạn đến mức bạn có thể làm được mà không cần tham khảo ở nơi khác.
Nếu bạn chưa biết, thì quên là một thành phần quan trọng của việc học. Mỗi khi bạn quên điều gì đó và học lại nó, nó sẽ đi vào não bạn sâu hơn và kỹ lưỡng hơn một chút.
Mỗi khi bạn học lại, não của bạn tạo ra những kết nối mới với những thứ khác bạn đã học được, giúp bạn hiểu thêm về bối cảnh của những gì bạn đang cố gắng làm.
Và mỗi khi bạn học lại, bạn sẽ làm cho bộ não của bạn rõ ràng rằng chủ đề cụ thể này đáng ghi vào bộ nhớ dài hạn của nó.
Nhưng nếu bạn bắt đầu cố gắng ghi nhớ mọi thứ, bạn sẽ gặp khó khăn.
Thay vào đó, đừng lo lắng về việc quên mọi thứ: biết nơi để tra cứu chúng quan trọng hơn nhiều so với việc ghi nhớ mã Swift cụ thể để hoàn thành một việc gì đó.
Khi bạn quên điều gì đó và phải học lại, tôi khuyến khích bạn nghĩ đó là một điều tốt – thông tin đó sẽ chìm sâu hơn vào lần thứ hai, thứ ba và thứ mười khi bạn học nó, vì vậy bạn đang giúp ích cho bộ não của mình.
Đừng màng tới SOS
Vấn đề thứ hai mà tôi thấy mọi người gặp phải là cái mà tôi gọi là hội chứng vật thể sáng bóng (shiny object syndrome) – họ tìm thấy một loạt hướng dẫn phù hợp với mình và bắt đầu đạt được một số tiến bộ, nhưng sau một hoặc hai tuần họ thấy một số loạt hướng dẫn khác mà họ muốn làm theo và nhảy qua đó.
Đã có người gửi email cho tôi nói rằng họ đã thử 4, 5 hoặc thậm chí 6 hướng dẫn khác nhau và – vì một số lý do kỳ lạ – nhận thấy rằng họ không học được gì.
Vấn đề ở đây thường là phần lớn việc học bất cứ thứ gì không thú vị.
Đó hoàn toàn không phải lỗi của giáo viên, đó chỉ là thực tế của việc học code – một số thứ mang lại cho bạn kết quả tuyệt vời mà hầu như không có tác dụng nào, và những thứ khác cần nhiều thời gian hơn để hiểu, không mang lại kết quả tốt hoặc chỉ là một phần của một khái niệm lớn hơn.
Khi bạn đạt được những đường cong học tập dốc này, SOS trở nên mạnh mẽ – với rất nhiều hướng dẫn miễn phí hiện nay, bạn có thể chuyển đến bất kỳ hướng dẫn nào trong số đó và bắt đầu lại, và ngay lập tức bạn sẽ quay lại đáy hồ một lần nữa, bao gồm các phần dễ hơn bạn đã học.
Nhưng trừ khi khóa học ban đầu chọn dạy về một chủ đề đặc biệt kỳ lạ, bạn kiểu gì rồi sẽ phải học nó và bạn chỉ đang trì hoãn một điều không thể tránh khỏi.
Vì vậy, không bắt buộc bạn luôn chống lại hội chứng vật thể sáng bóng, vì tôi biết điều đó rất khó.
Thay vào đó, ít nhất hãy ý thức về nó: khi bạn gặp vấn đề, hãy thử nhờ người khác giúp đỡ và vượt qua thay vì đổi đi đổi lại.
Đừng là một con sói đơn độc
Nói về việc hỏi người khác, vấn đề thứ ba mà tôi thấy mọi người gặp phải là khi họ hoàn toàn đơn độc với việc học của mình – họ nghĩ trong đầu rằng họ hoàn toàn có khả năng học cách tự xây dựng các ứng dụng iOS bằng Swift, và không cần sự giúp đỡ của người khác.
Cách tiếp cận này thực sự hiệu quả với một số lượng rất nhỏ người, thường là những người có nhiều kinh nghiệm với các ngôn ngữ lập trình hoặc nền tảng khác.
Nhưng đối với phần lớn mọi người, cố gắng học hỏi như thế này là một trải nghiệm khủng khiếp – mỗi sai lầm hoặc hiểu lầm mất gấp năm lần để tìm ra, cực kỳ dễ mất động lực và bạn đang bỏ lỡ rất nhiều cảm hứng từ việc nhìn thấy người khác thành công.
Nếu bạn tự nhiên thích phong cách học “sói đơn độc” này, hãy để tôi khuyến khích bạn thay đổi: chia sẻ những gì bạn đang học, tìm những người khác cũng đang học và tập thói quen đặt câu hỏi.
Bạn không chỉ khám phá ra có một cộng đồng tuyệt vời gồm những người học sẽ bao quanh bạn với sự hỗ trợ và khuyến khích, mà bạn còn được truyền cảm hứng từ công việc của họ và lần lượt truyền cảm hứng cho họ với công việc của bạn.
Tin tôi đi, tôi đã thấy điều này xảy ra hàng trăm lần và nó hoàn toàn biến đổi.
Chạy theo phiên bản beta
Vấn đề lớn thứ tư mà tôi thấy mọi người gặp phải là khi họ khăng khăng sử dụng phiên bản beta các công cụ phát triển của Apple.
Tôi hiểu: mỗi năm Apple đều giới thiệu iOS mới, macOS mới,… luôn mang đến những điều mới thú vị để chúng ta thử.
Hoàn toàn tự nhiên khi mọi người muốn tìm hiểu những gì mới nhất, tuyệt vời nhất ngoài kia, đặc biệt nếu họ biết rằng Swift có một lịch sử thay đổi lâu dài.
Tuy nhiên, mọi người gặp phải tất cả các loại vấn đề khi họ cố gắng học với phần mềm beta:
- Các bài học chưa được cập nhật cho phiên bản beta, vì vậy, việc làm theo các bài học không phải lúc nào cũng có thể thực hiện được hoặc có thể hoạt động không chính xác.
- Beta thường có rất nhiều lỗi, đặc biệt là đối với những phiên bản được phát hành cho các bản cập nhật iOS lớn.
- Các framework beta của Apple cần thời gian để ổn định, có nghĩa là code hoạt động trong phiên bản beta 1 có thể không tồn tại trong phiên bản beta 3.
Vì vậy, tôi biết thật thú vị khi tìm hiểu những thứ mới và tôi nhận ra rằng bạn có thể nghĩ rằng bạn đang dẫn đầu trò chơi với các tính năng mới, nhưng hãy tin tôi: điều đó không đáng.
Hãy luôn bám vào các bản phát hành công khai mới nhất của các công cụ dành cho nhà phát triển của Apple, ít nhất là cho đến khi bạn cảm thấy thoải mái với chúng.
Dựa vào các tài liệu chính thức
Vấn đề lớn thứ năm mà mọi người gặp phải khi cố gắng tìm hiểu là dựa vào tài liệu của Apple.
Nhóm xuất bản dành cho nhà phát triển của Apple làm việc chăm chỉ để ghi tài liệu nhiều nhất có thể từ rất nhiều framework của công ty, nhưng công việc của họ phần lớn là viết tài liệu tham khảo – những thứ bạn đọc khi đang cố gắng sử dụng một phần cụ thể trong công cụ của họ, thay vì tạo một khóa học có cấu trúc để giúp bạn học cách xây dựng ứng dụng iOS.
Tôi đã không nghe không biết bao nhiêu lần mọi người hỏi “làm thế nào tôi có thể học Swift?” chỉ để được trả lời “chỉ cần đọc hướng dẫn tham khảo Swift của Apple.”
Cách tiếp cận này thực sự hiệu quả với một số người và tôi biết điều đó vì nó phù hợp với tôi – tôi đã đọc nó từ đầu đến cuối khi Swift được công bố lần đầu tiên.
Tuy nhiên, đối với hầu hết mọi người, nó giống như cố gắng học ngôn ngữ của con người bằng cách đọc từ điển: nó được thiết kế để bao gồm mọi thứ bằng ngôn ngữ đó, thay vì dạy bạn những phần quan trọng nhất và cách áp dụng chúng.
Vì vậy, nếu bạn có nhiều kinh nghiệm với các ngôn ngữ khác, bạn có thể thấy việc đọc hướng dẫn tham khảo của Apple là hữu ích, nhưng nếu bạn mới bắt đầu thì có thể quay lại với chúng sau một vài tháng.
Bị lạc trong Objective-C
Vấn đề lớn thứ sáu mà mọi người gặp phải là cố gắng học Objective-C.
Đây là ngôn ngữ phát triển chính của Apple trước khi Swift được giới thiệu và mặc dù bạn sẽ tìm thấy tàn dư trong một số cơ sở mã cũ nhưng phần lớn mã hiện có hiện tại là Swift và hầu như tất cả mã mới cũng là Swift.
Tôi đã dành nhiều năm để viết Objective-C trước khi Swift xuất hiện và thực sự yêu thích nó, nhưng nó có quá trình học tập cực kỳ khó khăn so với Swift và bỏ lỡ hầu hết các tính năng quan trọng của Swift.
Tôi nhớ lần đầu tiên tôi dùng thử SDK iPhone khi Apple công bố nó, và cảm thấy kinh hoàng với Objective-C vì nó hoàn toàn không giống bất cứ thứ gì khác mà tôi đã thấy cho đến nay.
Đối với người học, Objective-C và Swift hầu như không có điểm chung.
Đúng vậy, cả hai đều có chung khuôn khổ của Apple, nhưng trừ khi bạn thực sự định làm việc tại Apple – công ty duy nhất trên thế giới vẫn sản xuất một lượng lớn Objective-C – thì bạn nên để Objective-C một bên và tập trung hoàn toàn vào Swift.
Biết một chút các ngôn ngữ khác
Và sai lầm lớn cuối cùng mà tôi thấy mọi người mắc phải khi học Swift là đổ lỗi cho các ngôn ngữ khác như thể chúng kém hơn Swift theo cách nào đó.
Mục tiêu thông thường là JavaScript, nhưng bạn cũng sẽ thấy mọi người nói cả Python, Java, Ruby, Go,… và để làm gì?
Đó không phải là một cuộc thi, các bạn ạ – những ngôn ngữ đó không cần phải thua thì Swift mới có thể chiến thắng.
Trên thực tế, Swift và SwiftUI lấy cảm hứng từ các ngôn ngữ và framework khác – bất cứ khi nào các tính năng ngôn ngữ mới được cân nhắc, cộng đồng sẽ nhìn vào các triển khai tương tự trong Rust, Python, Haskell và các ngôn ngữ khác, và bản thân SwiftUI được lấy cảm hứng từ framework React trong JavaScript.
Vì vậy, khi tôi thấy mọi người trong cộng đồng của chúng ta nói SwiftUI là không có JavaScript hoặc tương tự, tôi chỉ chùn tay – không có gì có thể đi xa hơn sự thật.
Các khóa học và tài nguyên dành cho nhà phát triển iOS
Bây giờ, phần mà hầu hết mọi người sẽ quan tâm nhất: tôi nghĩ bạn nên sử dụng tài nguyên thực tế nào để học Swift, SwiftUI và hơn thế nữa – để đạt được mục tiêu trở thành iOS Developer?
Có rất nhiều thứ ngoài kia, và tôi thực sự đánh giá cao thực tế là cộng đồng Swift có rất nhiều người chia sẻ kinh nghiệm của họ.

Tuy nhiên, ở đây tôi đặc biệt sẽ xem xét các tài nguyên miễn phí – những nơi bạn có thể đến và học cách xây dựng các ứng dụng tuyệt vời mà không phải trả một xu.
Có hai lý do cho việc này:
- Một số người tin rằng một khóa học Swift càng tốn kém thì càng tốt, vì vậy họ sẽ phải trả những cái giá quá đắt mà không nhận được đủ lợi ích từ nó.
- Nhiều trang web như Udemy dựa vào việc bán nhiều khóa học giá rẻ, tin rằng nếu bạn không thích một khóa học, bạn sẽ mua một khóa học khác. Họ cũng có mô hình kinh doanh tương tự như Steam’s – luôn có doanh số bán hàng, khuyến khích mọi người xây dựng nhiều khóa học mà họ sẽ học “một ngày nào đó”.
Vì vậy, tôi chỉ liệt kê các tài nguyên miễn phí ở đây bởi vì tôi không muốn bạn rơi vào những cái bẫy đó – đừng vung một trăm đô trở lên cho khóa học đầu tiên của bạn và đừng mua một tá khóa học rẻ tiền vì bạn nghĩ điều đó khiến bạn trở thành nhà phát triển.
Hướng dẫn có cấu trúc
Đầu tiên, Apple có hai tài nguyên lớn có thể giúp bạn.
Đầu tiên là trang Teaching Code, nơi liệt kê các tài nguyên dành cho sinh viên và giáo viên để học Swift từ cơ bản cho đến chứng chỉ chuyên nghiệp.
Chương trình học của họ rất lớn, vì vậy bạn có thể mất một chút thời gian để tìm ra điểm đầu vào tốt nhất cho mình, tuy nhiên khi bạn đã ở đó, bạn sẽ tìm thấy rất nhiều điều để khám phá.
Thứ hai, Apple có một loạt các hướng dẫn SwiftUI nhập môn giúp bạn xây dựng các ứng dụng thực tế.
Tuy nhiên, những cái này không dạy bạn Swift, vì vậy trước tiên bạn cần phải tuân theo chương trình giảng dạy tập trung vào Swift của họ.
Giống như tôi đã nói trước đó, Apple cũng tạo ra một hướng dẫn dành riêng cho ngôn ngữ lập trình Swift, nhưng rất có thể nó sẽ không phù hợp với bạn – nó được thiết kế như một tài liệu tham khảo chứ không phải là một hướng dẫn có cấu trúc, vì vậy nó khá dày đặc.
YouTube
Có một số video YouTube tuyệt vời hướng dẫn bạn về các nguyên tắc cơ bản của SwiftUI, bao gồm:
- Một từ Chris Ching, anh ấy hướng dẫn bạn xây dựng một trò chơi đánh bạc từ đầu.
- Một từ Mark Moeykens, anh ấy giải thích 5 khái niệm SwiftUI mà mọi người nên học khi bắt đầu lập trình.
- Và một từ tôi, tôi dạy cả Swift và SwiftUI cùng lúc, trong khi lấy câu hỏi từ khán giả.
Mặc dù chúng không có cấu trúc, nhưng vẫn có những trang web khác có hướng dẫn Swift và SwiftUI chất lượng cao, gồm BLCKBIRDS, Ray Wenderlich, Donny Wals, Antoine van der Lee,…
Tôi thực sự khuyến khích mọi người truy cập nhiều tài nguyên và tìm những gì phù hợp với mình.
Học từ ứng dụng
Nếu bạn thích học bằng cách sử dụng các ứng dụng, tôi muốn giới thiệu hai ứng dụng, cả hai đều hoàn toàn miễn phí.
Đầu tiên là ứng dụng Swift Playgrounds của Apple, cho phép bạn học Swift ngay trên iPad hoặc Mac của mình.
Có rất nhiều bài học tương tác dành cho trẻ em, nhưng cũng có một số bài học nâng cao hơn sẽ giúp thúc đẩy các kỹ năng của bạn hơn nữa.
Ứng dụng còn lại là do tôi tự tạo và có tên là Unwrap.
Unwrap hoạt động trên tất cả iPhone và iPad, đồng thời cho phép bạn tìm hiểu, đánh giá và thực hành các nguyên tắc cơ bản của Swift bằng cách sử dụng video, bài kiểm tra và hơn thế nữa.
Nó bao gồm tất cả các nguyên tắc cơ bản của Swift.
Tìm câu trả lời
Cuối cùng, bạn sẽ cần học cách tìm câu trả lời trực tuyến.
Điều này có thể có nghĩa là đến Stack Overflow, nhưng thành thật mà nói, tôi hy vọng không phải vì đó không phải là một nơi quá dễ chịu.
Thay vào đó, hãy đặt câu hỏi trên diễn đàn Hacking với Swift, trên nhóm Slack yêu thích của bạn, trong các phiên Giờ hạnh phúc dành cho iOS Developer, trên Twitter, v.v. – chúng ta thực sự là một cộng đồng rất nồng nhiệt, thân thiện với rất nhiều người sẵn sàng giúp bạn tiếp cận mục tiêu của bạn.
Kết nối với cộng đồng
Nói về cộng đồng của chúng tôi, tôi muốn chuyển sang một chủ đề thực sự quan trọng sẽ giúp gặp gỡ những người ở vị trí tương tự như bạn, giúp bạn học hiệu quả hơn và cũng giúp bạn tìm được cơ hội việc làm – tất cả chỉ là một chiến thắng.
Chủ đề là thế này: kết nối với cộng đồng phát triển iOS. Điều này nghĩa là học nơi tìm kiếm tin tức và những ý tưởng thú vị, đi đâu khi bạn muốn gặp gỡ mọi người và chia sẻ mẹo cũng như những nơi hữu ích để bạn có thể đặt câu hỏi.
Theo dõi ai trên Twitter?
Hãy bắt đầu với cách dễ nhất trước tiên, đó là sử dụng Twitter.
Twitter là một cách thực sự tuyệt vời để theo dõi những thứ bạn quan tâm và trong trường hợp phát triển iOS, tôi thực sự muốn giới thiệu một số người.
Những người này tweet về công việc của họ, nhưng lý do tôi nghĩ họ rất tuyệt khi theo dõi là vì họ cũng tweet rất nhiều về công việc của người khác – họ sẽ giúp bạn thấy nhiều góc nhìn về một chủ đề cụ thể và họ chia sẻ tất cả các loại ý tưởng thú vị và những điều để thử.
Có 10 người mà tôi khuyên bạn nên theo dõi trên Twitter:
- Sean Allen dành nhiều thời gian để tạo video trên YouTube về phát triển Swift và iOS, nhưng anh ấy cũng rất chăm chỉ truyền bá tin tức về những thứ mà những người khác đã tạo ra – anh ấy thực sự làm rất tốt việc giúp mọi người khám phá điều gì đó mới mỗi tuần.
- Antoine van der Lee điều hành một trang web dành riêng cho phát triển iOS tại https://www.avanderlee.com, nhưng anh ấy cũng chia sẻ một số liên kết tuyệt vời đến các tài nguyên hữu ích mà anh ấy tìm thấy trên GitHub, bản tin, v.v.
- Novall Khan làm việc tại Apple, nhưng điều đó không ngăn cản cô ấy tạo video thường xuyên về những gì cô ấy đang làm, những gì cô ấy đang học, những gì cô ấy gặp khó khăn và hơn thế nữa – cô ấy thực sự truyền cảm hứng.
- Steve Troughton-Smith nổi tiếng với công việc trước đây của anh ấy đã thử nghiệm trên iOS, nhưng thực sự bạn nên theo dõi anh ấy để biết về một loạt các dự án tuyệt vời mà anh ấy chia sẻ. Cá nhân tôi thích cách anh ấy chia sẻ tiến trình phát triển trên các ứng dụng của riêng mình, vì vậy bạn có thể thấy chúng phát triển từ đầu đến cuối.
- Kaya Thomas là một trong những nhà phát triển indie (độc lập) nổi tiếng nhất trong cộng đồng của chúng ta và đã được Apple giới thiệu nhiều lần hơn tôi có thể nhớ được. Cô ấy tweet rất nhiều về công việc và bài thuyết trình của mình, nhưng cũng chia sẻ các liên kết đến những cuốn sách mà cô ấy đang học, các bài báo cô ấy đã đọc và hơn thế nữa.
- Majid Jabrayilov viết một blog tuyệt vời về Swift và SwiftUI, nhưng anh ấy cũng là người quảng bá không mệt mỏi cho những người khác.
- Donny Wals viết blog Swift, cũng như gần đây viết sách Combine & Core Data, nhưng trên Twitter, anh ấy cũng khuyến khích mọi người chia sẻ những gì họ đang làm. Thậm chí chỉ cần đọc chủ đề đó mỗi tuần sẽ giúp bạn có nhiều thứ để thử, vì vậy bạn chắc chắn nên theo dõi Donny.
- Sommer Panage làm việc tại Apple trong nhóm hỗ trợ tiếp cận, vì vậy mặc dù cô ấy hơi bị hạn chế bởi những gì cô ấy có thể nói, cô ấy tweet ra rất nhiều mẹo hạng nhất từ bản thân và những người khác mà mọi người có thể sử dụng để xây dựng các ứng dụng tốt hơn.
- Natascha Fadeeva viết blog về sự phát triển của Swift và iOS, bao gồm các bài viết về Dữ liệu cốt lõi, câu hỏi phỏng vấn, v.v., nhưng cô ấy cũng tweet về những điều mà cô ấy đã khám phá được ở những nơi khác.
- Và cuối cùng là tôi. Tôi tweet rất nhiều về tất cả những thứ tôi đang làm với Swift, SwiftUI và hơn thế nữa, nhưng cũng cố gắng chia sẻ các bài báo, video và ứng dụng tuyệt vời mà những người khác đã làm – tôi nghĩ đó là một trong những điều quan trọng nhất tôi làm cộng đồng.
Bản tin
Tất nhiên, Twitter không phải là nơi duy nhất mà bạn có thể cập nhật cộng đồng – có các bản tin, nhóm Slack, buổi họp mặt Zoom, diễn đàn, hội nghị,…
Tôi không muốn làm phiền bạn quá nhiều, vì vậy tôi sẽ liệt kê một trong số những điều đó ở đây:
- Đối với bản tin, bạn không thể làm sai với iOS Dev Weekly. Khi tôi viết điều này, nó chỉ vượt qua 500 số báo, một số mỗi tuần, vì vậy tôi nghĩ rằng điều đó cho bạn biết tất cả những gì bạn cần biết về tầm quan trọng của nó.
- Nếu bạn muốn đăng trên một diễn đàn web, tôi tự tổ chức một diễn đàn tại https://www.hackingwithswift.com/forums – có rất nhiều danh mục để lựa chọn và mọi người đều có thể tham gia bất kể mức độ kinh nghiệm của bạn là gì. Hãy tin tôi, bạn được hoan nghênh đăng các câu hỏi dành cho người mới bắt đầu của bạn ở đây!
- Mỗi tháng Happy Hour dành cho iOS Developer diễn ra trên một cuộc gọi Zoom nhóm với hơn 300 người, nhưng điều thú vị thực sự ở đây là các phòng đột phá, nơi bạn có thể trò chuyện với các nhóm từ 6 đến 8 người cùng một lúc. Thật là vui và bạn sẽ kết bạn được.
- Việc tham dự các hội nghị trở nên khó khăn do Covid, nhưng WWDC của Apple đã gây được tiếng vang lớn vào năm ngoái và cũng có nhiều sự kiện cộng đồng diễn ra cùng với đó. Một nhóm bạn và tôi đã điều hành một kho lưu trữ GitHub để giúp liệt kê tất cả các sự kiện, bài báo khác và hơn thế nữa đã xảy ra – hãy kiểm tra!
- Và cuối cùng, nếu bạn muốn trò chuyện trên Slack nơi bạn có thể nhận được câu trả lời nhanh hơn, bạn có thể tham gia nhóm Hacking miễn phí với Swift Slack và tham gia một trong các kênh dành cho Swift, SwiftUI, giáo trình 100 Ngày của tôi, v.v.
Mất bao lâu?
Đây là một câu hỏi mà tôi nhận được rất nhiều câu hỏi: mất bao lâu để từ khi không biết gì về Swift để có thể có được vị trí nhà phát triển iOS cấp độ đầu vào.
Rõ ràng câu trả lời là “còn tùy”, nhưng đó sẽ là một cảnh sát ở đây, vì vậy hãy để tôi giải quyết nó theo một vài cách khác nhau.
Quy tắc vàng: đừng vội vàng
Đầu tiên, điều bạn không thể làm là vội vàng học nhiều khóa học cùng một lúc. Còn nhớ những gì tôi đã nói về hội chứng vật thể sáng bóng?
Vâng, điều đó – nhiều người thực sự nghĩ rằng họ có thể tăng gấp đôi với hai khóa học cùng lúc, sau đó gấp rút học qua bốn, năm, hoặc thậm chí nhiều giờ hơn mỗi ngày và vẫn có được sự hiểu biết chất lượng cao về các chủ đề mà họ đã đề cập.
Nói rõ hơn, tôi đã thấy mọi người thử điều đó rất nhiều lần và lần nào nó cũng thất bại.
Mỗi lần – nó không bao giờ hoạt động, và tôi thấy mọi người nói rằng đó là do hướng dẫn không tốt, hoặc vì Swift quá khó, hoặc vì bất kỳ lý do nào khác ngoài việc họ cố gắng chạy nhanh qua một thứ gì đó phức tạp.
Theo nghĩa đen, hôm nay tôi nhận được một email có nội dung “Xin chào Paul! Nếu tôi dành bốn hoặc năm giờ mỗi ngày để học Swift, tôi có thể hoàn thành nhanh đến mức nào? ”
Và đó không chỉ là cách học tập – không phải học Swift, không học chơi piano, không học trượt băng hay bất cứ điều gì.
Học Swift thực sự rất khó và học xây dựng ứng dụng cần rất nhiều lần thử và sai, rất nhiều lần mắc lỗi và rất nhiều lần sai.
Và điều đó không sao cả – tốt hơn cả không sao, mà là tuyệt!
Bởi vì mỗi lần bạn thử điều gì đó, mỗi lần bạn mắc lỗi và mỗi lần bạn đi sai, bạn sẽ học được điều gì đó trên đường đi và khi cuối cùng bạn đi đến giải pháp, bạn sẽ hiểu sâu hơn về nó.
Vì vậy, đừng cố gắng và vội vàng – hãy dành thời gian của bạn, đừng ngại khám phá những tiếp tuyến đi kèm, đừng ngại thử nghiệm với các dự án của bạn và đừng ngại đi quay lại điều gì đó bạn đã học trước đây và học lại nếu cần.
Nền tảng của bạn là gì?
Thứ hai, bạn nên cân nhắc xem bạn đã có nền tảng gì trước khi đến với Swift.
Bạn thấy đấy, học cách xây dựng ứng dụng đòi hỏi nhiều kỹ năng khác nhau và nếu bạn đang nắm bắt được nhiều kiến thức hiện có như kiểm soát phiên bản, cấu trúc dữ liệu, thuật toán,… thì bạn có một khởi đầu thực sự so với những người mới làm quen với khoa học máy tính nói chung cùng với việc mới biết tới Swift và các framework khác của Apple.
Vì vậy, chúng ta có thể nghĩ về một vài nơi khác nhau mà bạn có thể đang ở ngay bây giờ:
- Nếu bạn có bằng khoa học máy tính (Computer Science – CS), bạn đã nắm bắt nhiều nguyên tắc cơ bản về CS cần thiết để bắt đầu sử dụng Swift. Những thứ như biến, mảng, vòng lặp, tập hợp, hàm, OOP… đều sẽ hữu ích trong Swift, cũng như tất cả công việc của bạn với cấu trúc dữ liệu và thuật toán. Điều này có thể giảm được 4-6 tháng lộ trình học tập của bạn tùy vào môn bạn đã học, và cũng mang lại lợi thế cho bạn khi ứng tuyển tại nhiều công ty.
- Nếu bạn không có bằng CS nhưng đã tham gia khóa đào tạo về mã hóa, một lần nữa, bạn sẽ có nhiều nguyên tắc cơ bản cần thiết để bắt đầu sử dụng Swift. Điều này sẽ không mang lại cho bạn lợi thế tương tự khi nộp đơn xin việc tại các công ty đó, bởi vì thường họ mong đợi một tấm bằng theo đúng nghĩa đen để họ có thể kiểm tra danh sách các yêu cầu tùy ý của họ, nhưng nó vẫn có thể khiến bạn mất ba hoặc bốn tháng lộ trình học tập.
- Nếu bạn không có bằng CS và không tham gia bootcamp, nhưng bạn vẫn code trong thời gian rỗi, một lần nữa điều đó sẽ giúp bạn tiết kiệm được 1 khoảng thời gian trên lộ trình học tập – có thể là hai tháng hoặc lâu hơn, tùy thuộc vào ngôn ngữ hoặc framework nào bạn sử dụng.
Và điều gì sẽ xảy ra nếu bạn không có bằng CS, không có bootcamp và không có kinh nghiệm code trước đó?
Tôi muốn nói rằng bạn sẽ cần 9 đến 12 tháng để từ không có gì trở thành một công việc mới bắt đầu.
Vâng, đó có thể là cả năm làm việc cùng với bất kể công việc toàn thời gian hiện tại của bạn và đó chỉ là để bạn có được công việc đầu tiên với tư cách là iOS developer.
Có phải nó luôn luôn là một năm?
Không. Như tôi đã nói, bạn có thể giảm được từ 1 đến 6 tháng nếu bạn đã có kinh nghiệm trước đó.
Nếu bạn tính toán những con số tốt nhất cho cả hai bên – 9 tháng từ con số không cho đến một công việc đầu việc, cộng với giảm bớt 6 tháng để có bằng CS – và điều đó có nghĩa là bạn có thể được tuyển dụng chỉ trong 3 tháng, điều này thật đáng kinh ngạc.
Bây giờ, bạn có thể nghĩ rằng việc kiếm được công việc đầu tiên sau ba tháng là không thể, nhưng thực tế không phải vậy.
Tôi đã gặp một người đang theo khóa học của tôi, người đã kiếm được việc làm trước khi họ bước sang ngày thứ 50 – họ đã học đủ về phát triển ứng dụng trong vòng chưa đầy hai tháng, bởi vì họ đã nỗ lực để mỗi ngày đều có giá trị.
Vì vậy, bạn không cần bằng CS và bạn không cần bootcamp, mà bạn cần chuẩn bị để làm việc chăm chỉ.
Đừng quá nghiêm khắc với bản thân
Điều thứ ba tôi muốn giải quyết trước khi chúng ta tiếp tục là nói rằng “nhanh hay chậm thì đều được cả.”
John Lennon có một ca từ tuyệt vời mà tôi yêu thích, đó là “cuộc sống là những gì xảy ra khi bạn bận rộn với những kế hoạch khác”.
Thật là tuyệt vời nếu bạn có những kế hoạch lớn cho việc học và khát vọng lớn cho công việc mà bạn muốn có, nhưng đôi khi bạn mệt mỏi, đôi khi bạn căng thẳng, đôi khi mái nhà của bạn bắt đầu bị dột hoặc con chó của bạn cần phải đến bác sĩ thú y hoặc con bạn cần thêm trợ giúp để làm bài tập về nhà, hoặc bất cứ điều gì, và đó chỉ là cuộc sống.
Vì vậy, xin đừng gục ngã nếu bạn bị tụt lại với lịch trình học tập của mình, hoặc nếu bạn thấy mình thiếu một vài ngày hoặc thậm chí một vài tuần, v.v. – miễn là bạn kiên cường, bạn sẽ đạt được điều đó.
Nếu bạn làm việc cực kỳ chăm chỉ và có được công việc sau 50 ngày, điều đó thật tuyệt vời – bạn hoàn thành tốt!
Nếu bạn mất 500 ngày, điều đó cũng thật tuyệt vời và bạn cũng nên tự hào như vậy.
Rất tiếc, nếu bạn mất 5 năm, tôi biết có thể đó không phải là điều bạn muốn, nhưng kết quả cuối cùng vẫn như cũ và đó mới là điều quan trọng.
Chuẩn bị nộp đơn
Cuối cùng nhưng không kém phần quan trọng, nếu bạn tiến xa hơn một chút đến lộ trình học tập iOS của mình và bắt đầu nghĩ đến việc kiếm được công việc đầu tiên đó, tôi muốn hướng dẫn bạn đến một bộ sưu tập khổng lồ các tài nguyên mà tôi đã tập hợp để giúp bạn.
Trên trang web của tôi, bạn có thể nhấp vào Tuyển dụng > Bắt đầu tại đây hoặc chỉ cần truy cập trực tiếp vào https://www.hackingwithswift.com/career-guide.
Ở đó, bạn sẽ tìm thấy một bộ sưu tập tài nguyên hoành tráng sẽ giúp bạn bất kể bạn ở đâu, tất cả đều miễn phí:
- Đánh giá kỹ năng tương tác để kiểm tra kiến thức của bạn về các chủ đề cốt lõi.
- Các bài kiểm tra mã hóa được sử dụng trên khắp thế giới trong các cuộc phỏng vấn việc làm thực tế.
- Hơn 200 câu hỏi phỏng vấn thường được sử dụng, cùng với các gợi ý về cách bạn có thể trả lời chúng.
- Các bài viết về cách tìm việc làm, cách làm tốt nhất của bạn trong các cuộc phỏng vấn và hơn thế nữa.
- Chỉ cần truy cập URL và bạn sẽ tìm thấy các liên kết đến tất cả những thứ đó và hơn thế nữa ở một nơi.
Tôi cũng muốn hướng bạn đến loạt video về mẹo phỏng vấn Swift của Sean Allen – anh ấy có toàn bộ danh sách phát để bạn có thể làm việc thông qua các cuộc thảo luận riêng lẻ, chẳng hạn như lớp học so với cấu trúc, lập trình chức năng, xử lý lỗi,…
Không có video nào là quá dài, nhưng mỗi video đều nhằm cung cấp cho bạn những kỹ năng cần thiết để thực hiện tốt một kịch bản phỏng vấn.
Bây giờ đang ở đâu?
Được rồi, vậy là tôi đã điểm qua các kỹ năng cốt lõi và mở rộng mà bạn cần, những sai lầm phổ biến mà mọi người thường mắc phải khi học, những khóa học nào bạn có thể theo, cách kết nối với cộng đồng iOS và cách chuẩn bị cho cuộc phỏng vấn xin việc của bạn – đó là một số lượng lớn để vượt qua và tôi hy vọng nó hữu ích.
Hơn nữa, tôi hy vọng tôi đã cho bạn thấy có bao nhiêu là hoàn toàn miễn phí.
Vâng, tôi biết sự cám dỗ rất mạnh mẽ khi vung ra một trăm đô trở lên cho một khóa học, nhưng hãy thư giãn – trước tiên hãy di chuyển, tìm động lực và cũng có thể tìm một người dạy Swift theo cách phù hợp với bạn.
Và sau đó, khi bạn đang ở một nơi tốt và cảm thấy sẵn sàng: hãy tiếp tục và chi tiêu một số tiền nếu bạn muốn.
Chúc bạn may mắn với hành trình của mình!
Nguồn: Hackingwithswift